

Actores contra la IA y el futuro de los chatbots
Noticias recientes de Inteligencia Artificial que importan a los negocios

En esta edición de Explicable, hablamos de la campaña que ha lanzado un sindicato de actores de Reino Unido en contra de los usos de la IA en el mundo de las artes escénicas. Conoceremos qué está haciendo EE.UU. para elaborar una ley que regule el uso de la IA, tras los pasos de Europa y China. También, para los que se preguntan dónde están los límites de la IA actual, analizaremos un conjunto de datos diseñado a propósito para que los grandes modelos de IA fallen en tareas de comprensión, triviales para cualquier humano. Y por último, veremos hacia dónde deberían evolucionar los chatbots actuales para que nos puedan ser realmente útiles.
Aprende a incorporar la Inteligencia Artificial de manera estratégica en tu proyecto profesional. ¿Conoces nuestro MásterIIA? Por ser suscriptor de Explicable podrás beneficiarte de un descuento. Utiliza el cupón EXPLICABLE300.
Actores de Reino Unido contra la IA
La semana pasada mostramos cómo la Inteligencia Artificial está empezando a transformar una industria tan establecida como es el cine, algo que no se vaticinaba cuando llegó la revolución del deep learning. Porque los últimos avances en los modelos generativos permiten utilizar la IA para sintetizar imágenes y sonido con una calidad cada vez mayor, que en algún momento será indistinguible de la realidad. Esto va a provocar que las características que nos atraen de la voz y la imagen que proyecta un actor se puedan replicar artificialmente en cualquier escenario. Y esto es precisamente contra lo que los actores se han movilizado, ante la amenaza de que muchos de ellos pierdan su trabajo, con una campaña llamada “Impide que la IA nos robe la actuación”.

Especialmente preocupante para este gremio es la situación de los actores de doblaje, debido a que la capacidad de sintetizar cualquier voz mediante IA es ya una realidad.
En el comunicado llegan a hablar de “consecuencias distópicas” para los actores, si se permite que esta tecnología se introduzca en la industria del entretenimiento.
Estos movimientos son comprensibles ante la llegada de una tecnología nueva, y han ocurrido frecuentemente a lo largo de la historia. La primera referencia la hallamos en el siglo XIX con la llegada de los telares, lo cual originó un movimiento denominado ludismo que promovía la destrucción de la maquinaria textil. También tenemos ejemplos más recientes con la llegada de los ordenadores, Internet, los móviles, las redes sociales, etc.
El rechazo a la tecnología del ludismo se fundamenta en la pérdida de puestos de trabajo, algo que muchos consideran una falacia, pues a lo largo de la historia, la desaparición de trabajos siempre se ha visto compensada por la aparición de nuevos trabajos que no se podían imaginar. Sin embargo, con la Inteligencia Artificial, este escenario optimista de creación de nuevos trabajos no resulta tan evidente. Por ejemplo, si la automatización llega de golpe a todas las industrias, las consecuencias podrían ser devastadoras a corto plazo, dado que la organización de nuestra sociedad no puede cambiar a gran velocidad. Predecir el futuro es imposible, pero es de vital importancia estudiar el impacto socioeconómico que puede traer un alto grado de automatización mediante IA, para responder a los cambios de la mejor manera posible. Porque nos guste o no, lo que sí que nos ha enseñado la historia es que el progreso tecnológico es un proceso imparable.
Más información: https://www.equity.org.uk/getting-involved/campaigns/stop-ai-stealing-the-show/
EE.UU. también quiere regular la IA
Siguiendo la estela de Europa y China, EE.UU. ha comenzado a posicionarse en el panorama mundial de la regulación sobre Inteligencia Artificial. En abril de 2021, la Comisión Europea presentaba el borrador de una proposición para regular la IA en los países de la Unión Europea. Esta regulación aplica a todos los sistemas basados en IA, definidos de una forma muy genérica, algo que ha sido muy controvertido. Además, el documento establece los requisitos que deben cumplir según el nivel de riesgo que supongan para las personas. Por otro lado, el 1 de marzo de 2022 entró en vigor la ley china que regula el uso de algoritmos de recomendación de contenidos, de filtrado de búsquedas y de ajuste dinámico de precios, para que sean transparentes y no discriminen. En otra proposición de ley, China también pretende regular el uso de modelos generativos capaces de sintetizar cualquier voz, crear fake news y deepfakes con el objetivo de engañar o dañar la reputación de las personas.

La aproximación de Europa ha sido regular la IA de forma amplia, tratando de cubrir todas las aplicaciones de la IA con la misma regulación. China ha apostado por hacerlo caso por caso, aglutinando aplicaciones de consecuencias similares bajo el mismo paraguas legal. No sabemos la aproximación que se adoptará en Estados Unidos para esta ley de carácter nacional; lo que sí sabemos es la composición de los 27 miembros del consejo asesor, que incluye a ejecutivos de empresas líderes en IA, como Google o NVIDIA, y personal de universidades como Stanford o Carnegie Mellon, pioneras de la IA en el mundo académico estadounidense. La participación directa del sector privado nos parece un acierto, algo que no parece haber estado tan presente en las regulaciones de China y Europa.
En un tema tan estratégico como la IA es importante no regular a espaldas del mundo de las empresas, para evitar leyes que frenen la innovación o generen situaciones de desventaja competitiva entre países.
Más información: https://www.axios.com/biden-administration-ai-national-artificial-intelligence-advisory-committee-07edc844-af8a-4df5-aadd-2800b6a42ff2.html
Lo que la IA aún no puede comprender
Desde la aparición de GPT-3, hemos asistido a una explosión de grandes modelos de Inteligencia Artificial, con una capacidad para comprender el lenguaje que, no hace mucho, se antojaba imposible. Aún así, son muchas las voces del mundo académico que critican estos modelos, argumentando que en realidad no comprenden nada y llamándolos, peyorativamente, “loros estocásticos”. Pero también aparecen trabajos académicos como el que vamos a mostrar hoy, orientados a encontrar esos límites donde la IA no es capaz de comprender y que serán muy útiles para medir el progreso futuro. Esta colaboración de empresas y universidades ha dado lugar a Winoground, una tarea de razonamiento junto con un conjunto de datos, los cuales están expresamente elegidos para explorar esos límites en la comprensión, que hoy sólo nuestra inteligencia puede resolver.
La tarea consiste en, dadas dos imágenes y dos descripciones, asociarlas con un grado alto de certeza, algo muy sencillo para los modelos como CLIP, entrenados con millones de pares de imágenes y texto. Pero la tarea se complica cuando las descripciones contienen las mismas palabras y es el orden de las mismas el que desentraña su significado. En el ejemplo mostrado a continuación, podemos ver la imagen de una bombilla rodeada de plantas y la imagen de una bombilla rodeando unas plantas. Si nos fijamos en el texto en inglés, ambos contienen exactamente las mismas palabras, pero en diferente orden.
Aquí es donde los modelos de IA actuales exponen sus limitaciones, dado que aún no son capaces de distinguir estas sutilezas del lenguaje, algo por otro lado trivial para nosotros.

El conjunto de datos de Winoground contiene 400 ejemplos como este, que explotan estas limitaciones. Para considerar que se resuelve la tarea, se miden los grados de certeza que produce el modelo para cada una de las 4 combinaciones de imagen y texto. Resolver estos casos frontera no es algo imprescindible para explotar el gran potencial de los modelos de imagen y texto, como podemos observar con un proyecto del calibre de DallE·2. Pero ilustra muy bien hasta dónde llega el estado del arte, y hacia dónde tiene que avanzar la investigación con el fin de seguir mejorando las prestaciones de estos modelos en el futuro.
Más información: https://arxiv.org/abs/2204.03162
Chatbots más listos
La mayoría de las veces que interaccionamos con uno de los chatbots que inundan las webs de hoy en día, nos quedamos con una sensación de gran frustración. Observamos cómo una tecnología, que prometía revolucionar áreas como la atención al cliente de las empresas, no es capaz de generar una experiencia de usuario positiva que perdure en el tiempo. Esto es debido a que los chatbots actuales están entrenados para reconocer un número limitado de intenciones del usuario. Y no siempre son capaces de identificarlas bien, debido a la infinidad de formas que tenemos de presentarlas. Por eso, muchas veces, la utilidad de un chatbot depende más del trabajo de los lingüistas, que enseñan a los modelos a detectar esas intenciones utilizando todos los posibles giros del lenguaje, que del trabajo de los ingenieros que ajustan los modelos de IA que funcionan por debajo.
Un chatbot verdaderamente inteligente debería tener una mayor capacidad de comprensión del lenguaje y debería de poder entender intenciones más allá de una lista predefinida. Los asistentes virtuales, como Siri o Alexa, tienen un catálogo de intenciones más amplio, pero aún así las limitaciones son evidentes y el nivel de frustración sigue presente. Recientemente estamos observando cómo los modelos de lenguaje universales muestran niveles de comprensión y razonamiento cada vez más altos. El problema es que son estáticos y no son capaces de ampliar la información más allá de la que han visto durante su entrenamiento.
La pregunta es, ¿cómo podríamos aprovechar las ventajas de estos grandes modelos de lenguaje para que respondan a preguntas abiertas?
Es lo que trata de conseguir la empresa AI21 Labs, que ha creado un sistema que mezcla un gran modelo de lenguaje con computación simbólica para refinar las respuestas del primero, mediante nuevos datos obtenidos de varias fuentes en tiempo real como, por ejemplo, la información meteorológica.
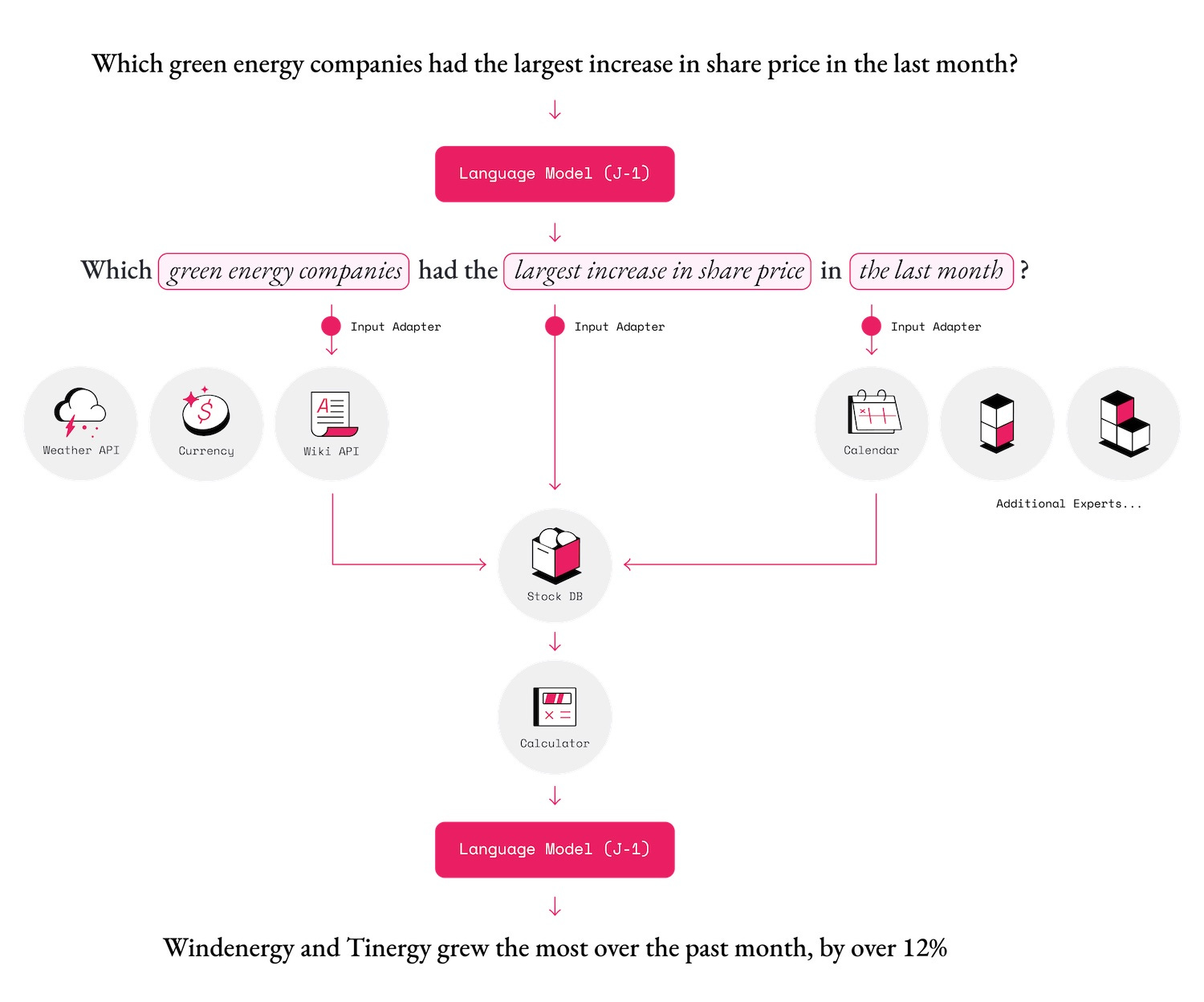
Esta idea no es nueva. A principios de este año, Google mostraba algo similar con su modelo conversacional LaMDA. A pesar de que estos modelos todavía se encuentran en fase de investigación, el potencial para los negocios es enorme. Por ejemplo, se podría utilizar para extraer información de documentos muy extensos de manera automática y facilitar el proceso de onboarding de empleados en empresas que generan mucha documentación. También podrían servir para la creación de asistentes virtuales que nos ayuden en las micro-decisiones que tomamos día a día, utilizando toda la información a su alcance. En los últimos 10 años, hemos visto avances increíbles en el campo de la IA. Sin embargo, todavía no existe una máquina con la que podamos trabajar codo con codo, y en todos los escenarios a los que nos enfrentamos. La semilla está plantada con esfuerzos como este, y el futuro de la IA no puede ser más apasionante.
Más información: https://www.ai21.com/blog/jurassic-x-crossing-the-neuro-symbolic-chasm-with-the-mrkl-system