

El verano de la IA
Noticias de inteligencia artificial que importan a los negocios

Ni el periodo estival ha sido capaz de frenar el espectacular avance de la inteligencia artificial que estamos viviendo este año. Sin duda, el protagonista de este verano ha sido Emad Mostaque, un experto en fondos de inversión que ha dado un giro a su carrera al financiar Stability.ai, la mayor iniciativa open source de IA que conocemos hasta el momento. En este Explicable veremos en qué consiste esta iniciativa y qué impacto puede tener en el desarrollo de startups basadas en IA. Además, veremos cómo otros laboratorios de IA aplicada siguen contribuyendo con nuevas ideas a este avance, que demuestra que el deep learning todavía no ha tocado techo y el supuesto invierno de la IA, que algunos auguran, se ve muy lejano.
Stable Diffusion y la explosión creativa
El movimiento de código abierto, open source en inglés, ha sido el principal artífice del crecimiento del ecosistema de startups que hemos presenciado en los últimos 20 años. Además, empresas de gran tamaño como Google y Facebook no sólo han basado sus productos en open source de terceros, sino que también participan del movimiento publicando librerías y herramientas propias que benefician a toda la comunidad. Y Google también obtiene un beneficio de vuelta, pues el código fuente liberado mejora cuando se deja en manos de esta comunidad. Este cambio de paradigma también ha calado en empresas como Microsoft, que inicialmente se burlaba de la idea de que alguien pudiera confiar en aplicaciones basadas en open source, y que ha acabado por comprar Github, el mayor repositorio de código abierto del mundo. La cultura open source también ha estado detrás del carácter abierto y de la rápida difusión del deep learning en los primeros años, pero se ha encontrado con un obstáculo que hasta ahora era infranqueable: cómo compartir las extraordinarias prestaciones de los grandes modelos tipo Dall-E 2, GPT-3, LaMDA y GATO, entre otros.
Y es que el entrenamiento de estos grandes modelos precisa de una inversión del orden de millones de dólares, debido, principalmente, al coste de la infraestructura de hardware necesaria. Por este motivo, la organización que acomete la inversión no comparte el modelo una vez entrenado (y muchas veces tampoco los datos), y establece un sistema de pago por uso para poder rentabilizarlo. Esto restringe la posibilidad de construir nuevas aplicaciones basadas en modificaciones sobre dicho modelo, que es la base de la filosofía open source. Emad Mostaque se ha dado cuenta de esta limitación y ha cambiado la historia al sufragar la infraestructura de su bolsillo, con el propósito de que los grandes modelos estén a disposición de toda la comunidad.

El primer gran modelo que ha compartido bajo el paraguas del proyecto Stability.ai ha sido StableDiffusion, el equivalente open source de Dall-E 2. ¿Y qué ha ocurrido desde entonces? Desde el punto de vista artístico, hemos entrado en una explosión de creatividad sin precedentes. El arte digital nunca había estado al alcance de tantas personas, independientemente de su habilidad para plasmar en un papel las ideas de su cabeza. Y, desde el punto de vista tecnológico, poner este modelo en manos de la comunidad crea un ecosistema de aplicaciones imposible de imaginar, aprovechando el ingenio y el esfuerzo colaborativo de muchas personas. Esto crea un círculo virtuoso que permite mejorar la tecnología de forma muy rápida, al quedar expuestas la limitaciones que se van encontrando en las nuevas aplicaciones. Y, además, sin impedir que se pueda hacer negocio con todo ello, pues la valoración de Stability.ai se estima en 1000 millones de dólares. Es decir, la misma fórmula del éxito del open source, finalmente aplicada en toda su extensión al mundo de los grandes modelos de inteligencia artificial.
La publicación de este modelo no viene exenta de polémica. Por un lado, ha añadido más leña a la reclamación sobre los derechos de autor de las obras de arte utilizadas en el entrenamiento de estos grandes modelos. Los artistas hablan de “arte robado por la IA”, sobre todo a raíz de que una de estas imágenes generada por IA haya ganado el primer premio en un concurso de arte digital. El mundo del derecho debe pronunciarse sobre si la IA produce obras únicas inspiradas en otras, tal y como hacemos los humanos, o por el contrario produce un trabajo derivado de otros muchos, en cuyo caso habría que considerar los derechos de autor de estos. Lo lógico sería aplicar las mismas normas que rigen el arte producido por las personas, donde un juez puede determinar si una se deriva de otra en base a la similitud.
La segunda polémica viene del hecho de que no exista un filtro que controle las imágenes producidas para evitar un uso malicioso o que se reproduzcan los estereotipos no deseados de la sociedad.
Aquí entramos una vez más en la pretensión de imponer una ética concreta en la tecnología sólo cuando está basada en IA: sin poner en la balanza sus beneficios, tratando a todos sus usuarios como no dignos de confianza y exigiendo control a los creadores de dicha tecnología.
Es como si Adobe fuera responsable de lo que se produce en Photoshop y tuviera que filtrar imágenes ofensivas para que no pudieran editarse con su herramienta. Es importante sacar a la luz los impactos éticos de cualquier cambio de paradigma como este, pero quizá la primera pregunta sea: ¿quién es responsable del mal uso? Por eso, la licencia de StableDiffusion sólo impone la obligación de hacer un uso responsable y ético de la herramienta.
Más info: https://stability.ai/blog/stable-diffusion-announcement
Ordena y la IA ACTúa
Hace unos meses hablamos en Explicable de la fundación de la empresa Adept, cuyo objetivo es lograr la Inteligencia Artificial General (AGI), al igual que las empresas OpenAI y Deepmind. El motivo por el que nos hicimos eco fue por la lista de fundadores, todos con perfiles top en empresas como Google, Deepmind, OpenAI y Meta, entre los que se encontraban los inventores de la arquitectura Transformer que ha revolucionado el deep learning en los últimos 5 años. Adept acaba de presentar su particular aproximación para lograr el objetivo final de la AGI, con un modelo llamado ACT, que convierte instrucciones descritas en lenguaje natural en acciones que se aplican en un ordenador para realizar una tarea. La automatización de tareas en el mundo digital se conoce como RPA (Robot Process Automation). Normalmente requiere de un experto que, mediante comandos, imite las acciones que haría un humano de manera precisa y con cierta inteligencia para adaptarse a múltiples escenarios.
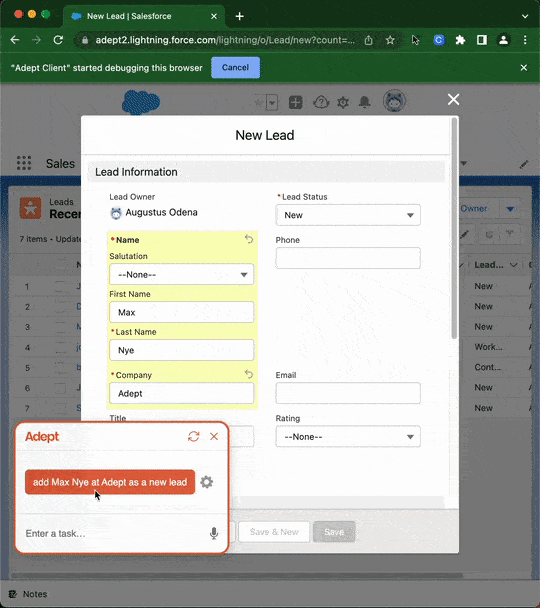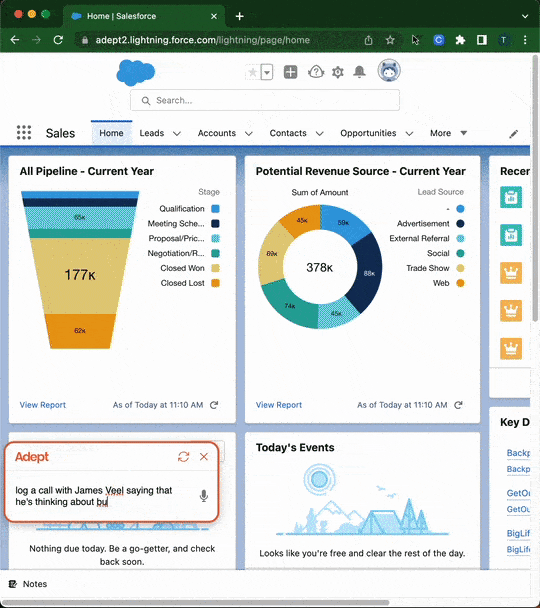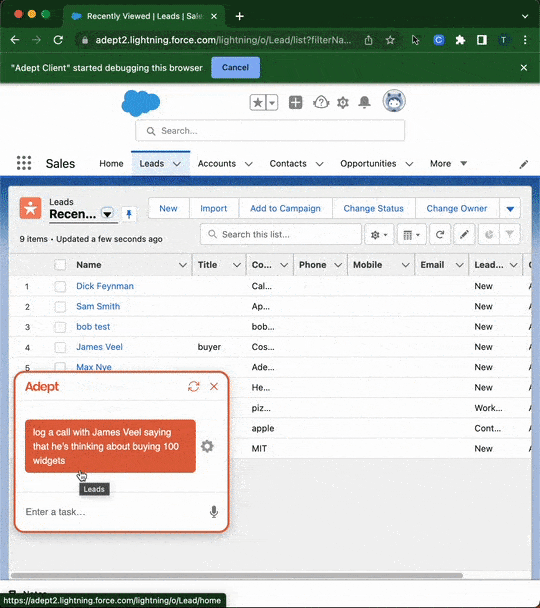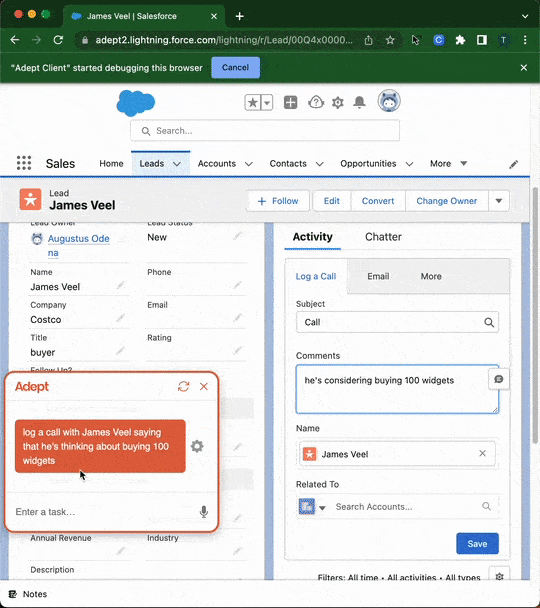
Con ACT, se elimina la necesidad de ese experto, ya que el modelo entiende las instrucciones y genera los comandos de manera autónoma. Además de la capacidad de automatizar tareas repetitivas como hace RPA, ACT está llamado a convertirse en el futuro interfaz para interactuar con una máquina, eliminando el ratón y teclado para hacernos más productivos frente a un ordenador. Y este punto es lo que hace que ACT sea revolucionario. De momento sólo está accesible en modo de beta-testing, y no han publicado ningún resultado que permita conocer cómo de cerca estamos de una futura comercialización.
Más info: https://www.adept.ai/act
Minerva aprende matemáticas
Muchos desconocen que la Inteligencia Artificial existe desde hace muchos años como disciplina dentro de las ciencias de la computación. Los científicos que entonces se dedicaban a ello lo hacían, principalmente, desde el enfoque simbólico, que consiste en lograr comportamiento inteligente a partir de la manipulación de símbolos que representan ideas o conceptos. El enfoque simbólico de la IA trata pues de replicar mediante computación cómo funciona nuestro pensamiento, que representa la capa de abstracción más alta de nuestro cerebro. Bajo esa capa de abstracción, sólo existe un sustrato físico basado en neuronas. Por contra, el enfoque conexionista trata de replicar ese nivel de abstracción utilizando únicamente neuronas artificiales, y, durante muchos años, estuvo denostado por los pobres resultados obtenidos.
Sin embargo, desde la irrupción de las redes neuronales profundas en la última década, la disciplina ha virado totalmente hacia el enfoque conexionista, con unos resultados que han puesto a la IA en el foco de atención a escala mundial. A pesar de esto, todavía existen voces dentro del ámbito académico que critican el deep learning, basándose en el hecho de que no puede resolver problemas simbólicos. Minerva, un modelo puramente conexionista de Google, es un camino muy prometedor que responde a esta crítica atacando la mayor fuente de problemas simbólicos que tenemos: las matemáticas.

Minerva está basado en un modelo de lenguaje propiedad de Google que, mediante ajuste fino, han adaptado para resolver problemas matemáticos.
Además de aprender a manipular símbolos, el modelo interpreta el enunciado del problema y devuelve una respuesta razonada de los pasos que ha seguido en la resolución. Todo ello sin acceso a bases de conocimiento externas, ni tan siquiera a una calculadora para realizar operaciones.
Los resultados indican que Minerva encuentra la solución correctamente para el 50% de los problemas matemáticos del conjunto de evaluación. Aunque todavía queda mucho camino por recorrer, el resultado es un paso importante, teniendo en cuenta que el mejor modelo anterior sólo conseguía resolver el 7% de problemas. No estaría de más comparar estos resultados con los que obtiene un ciudadano medio con este mismo conjunto de problemas, pero eso lo dejamos para otro tipo de foros.
Más info: https://ai.googleblog.com/2022/06/minerva-solving-quantitative-reasoning.html
AudioLM: modelo de audio universal
AudioLM es un GPT-3 para audio, es decir, es un modelo de lenguaje donde los tokens de información son fragmentos de audio en vez de palabras. Una vez entrenado, el modelo es capaz de continuar cualquier audio, ya sea voz o música, de manera coherente y con la posibilidad también de guiarlo mediante texto.
El audio contiene mucha más densidad de información por token que el texto, lo cual hace que los modelos de lenguaje pierdan fácilmente el contexto cuando se entrenan para generar audio.
Es decir, acústicamente es consistente, pero la estructura es inconsistente: por ejemplo, en voz aparecen fallos sintácticos o semánticos, y en música no se mantiene la forma de una obra musical.

AudioLM soluciona este problema de consistencia con una técnica nueva que garantiza que la información del largo plazo no se pierda durante la generación. Al igual que GPT-3 revolucionó el campo de procesamiento de lenguaje natural, este tipo de modelos hará lo mismo en el audio. AudioLM es propiedad de Google. En este sentido, una versión open source que hoy ya vemos plausible gracias a Stability.ai, podría habilitar un sinfín de aplicaciones de audio como la traducción simultánea, generación de voz sintética con expresividad, composición musical, etc. Los resultados, que sí han publicado, son muy reveladores de lo rápido que está avanzando la IA aplicada al audio.
Más info: https://google-research.github.io/seanet/audiolm/examples/
Gracias por leer Explicable. Si te ha gustado esta edición, no te olvides de dar al ♡ y de compartirla por redes sociales o por email con otras personas a las que creas que les pueda gustar.