

Winter is NOT coming ☀️
Noticias recientes de Inteligencia Artificial que importan a los negocios

En 2012 dio comienzo el boom de la Inteligencia Artificial, tras el momento Imagenet. Fueron muchas las predicciones que se hicieron entonces. 10 años después podemos ver cómo la IA ha evolucionado por derroteros distintos a los que se pronosticaban. Por ejemplo, a pesar de que las máquinas ya pueden entender una escena a partir de un vídeo con muy buena precisión, la conducción autónoma todavía no está desplegada a nivel masivo. También se decía que las máquinas nunca podrían llegar al nivel de creatividad humano, y desde entonces tenemos modelos que incluso lo superan en áreas concretas, como la generación de imágenes o la elección de estrategias en el ajedrez. Por tanto, hacer predicciones de la evolución de la Inteligencia Artificial durante los próximos 10 años es un esfuerzo poco útil. Lo que sí que es un hecho es que 2022 ha sido un año de sorprendentes avances, y 2023 como veremos a continuación sigue el mismo camino. El fantasma del nuevo invierno de la Inteligencia Artificial se aleja, a pesar de que todavía existen voces que lo siguen pronosticando. La Inteligencia Artificial, a diferencia de otras tecnologías de vanguardia como el blockchain o la computación cuántica, ya está generando valor en todos los sectores de la economía.
🚀 Si quieres formarte en IA, este es tu momento. Acabamos de lanzar la 6ª edición de nuestro Máster Ejecutivo en Inteligencia Artificial, una formación práctica diseñada por y para profesionales. 100% online, sin requisitos técnicos y en castellano. Y si, además, eres lector de Explicable, te ofrecemos un descuento adicional al precio promocional de lanzamiento. Utiliza: EXPLICABLE300
Vall-E imita cualquier voz
La apuesta de Microsoft por la Inteligencia Artificial se remonta a mucho tiempo antes de que la IA fuera mainstream a través de centro de investigación Microsoft Research, fundado en 1991. Este centro ha sido una fuerza importante en el desarrollo de la inteligencia artificial, contribuyendo al avance del deep learning y a la creación de productos de Microsoft como Kinect, Cortana o Bing. Sin embargo, en los últimos años no ha acaparado portadas en los medios de comunicación como sí lo han hecho Deepmind, OpenAI o Meta AI con la publicación de sus super modelos. Este año se disponen a cambiar esta tendencia con la publicación de Vall-E, un modelo que permite convertir cualquier texto en un audio de voz, lo que se conoce como un sistema TTS (text-to-speech). Este trabajo presenta una arquitectura novedosa, que es capaz de generar la voz con el mismo timbre que un audio de 3 segundos que se le indica como muestra. De esta manera, Vall-E es capaz de clonar cualquier voz al instante y sin requerir entrenamiento extra. Y además de extraer las características particulares del timbre de voz, también aplica la entonación y los matices expresivos de esos 3 segundos de muestra, produciendo como resultado una voz más natural y con capacidad de transmitir emociones.
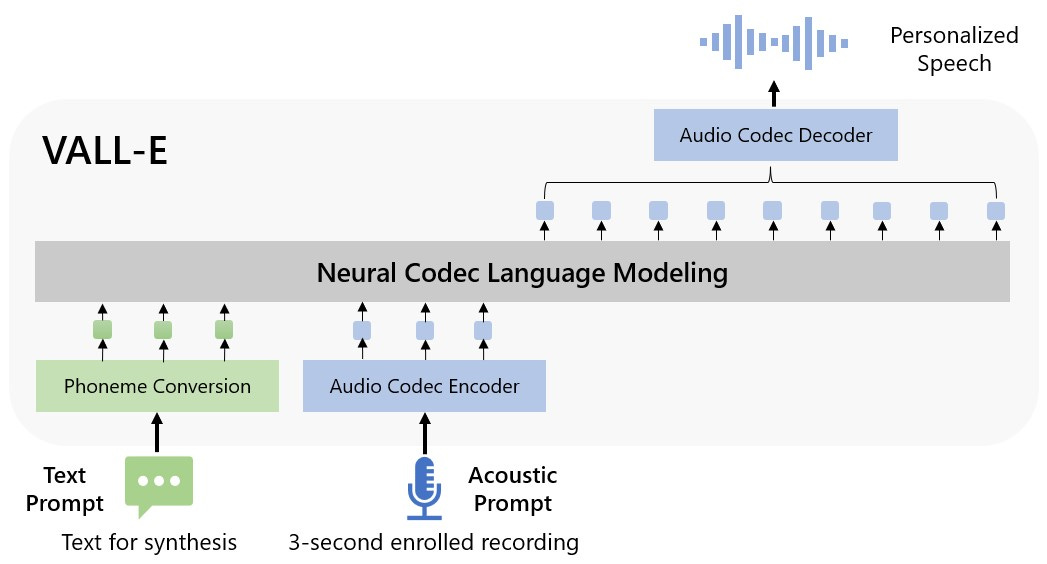
Evaluar los modelos de IA generativa para imagen o audio es una tarea complicada. No existe una métrica objetiva que podamos utilizar para comparar la salida de dos modelos ante la misma entrada. Por tanto, la única alternativa es utilizar la valoración subjetiva de varias personas, y hacer la media de las observaciones para obtener un resultado lo más objetivo posible. El artículo científico que acompaña a esta publicación ha analizado los resultados mediante este métrica llamada MOS (Mean Opinion Score), confirmando que mejora a todos sus antecesores. Desafortunadamente, no podemos probar Vall-E porque no han publicado el modelo entrenado. Sin embargo, en los ejemplos que sí han publicado, se aprecia una mejora de la calidad con respecto al estado del arte. Aunque todavía no es comparable a la voz que producimos los humanos, que sí somos capaces de adaptar el tono de la voz en cada sílaba que pronunciamos para transmitir. Esto es lo que conocemos como comunicación no verbal, algo que por el momento está ausente en los sistemas TTS.
Estos modelos tienen muchísimos beneficios, como por ejemplo la generación de voz para interaccionar de una forma más natural con asistentes virtuales, como ayuda a las personas que tienen dificultades en el habla, o para producir audiolibros de forma automática, tal y cómo ha anunciado Apple recientemente.
Pero también implican nuevos riesgos; por ejemplo, se podrían utilizar para realizar transacciones no autorizadas mediante la suplantación de una persona, como ya ocurrió en 2019 en Reino Unido. Además de perseguir este tipo de conductas delictivas con una legislación adaptada a los nuevos tiempos, la sociedad también debe adaptarse a vivir en un mundo donde la clonación de voz es una realidad y no se acepte todo el contenido audiovisual que recibe. Por ejemplo, se abre la posibilidad de un futuro donde el contenido que consumimos, principalmente vídeo, venga firmado con un certificado que garantice su autenticidad. Del mismo modo que antes de la llegada de Internet ya existía una prensa diversa e independiente, la cual arriesgaba su reputación con cada noticia que publicaba.
Más info: https://valle-demo.github.io
LLMs que van a la universidad
ChatGPT ha sido la chispa que necesitaban los LLMs (Large Language Models) para volver a estar de moda en este 2023. Hay mucha polémica en la comunidad científica sobre si estamos ante una mejora incremental o un salto tecnológico inesperado. Pero lo cierto es que ChatGPT es el resultado de avances importantes en el campo de NLP que han sucedido durante 2022, como InstructGPT o Chinchilla, a la sombra de los populares modelos de generación de imágenes, como Dall-E o Stable Diffusion. Sabemos que ChatGPT tiene al menos dos limitaciones importantes: por un lado, la información que produce no siempre es veraz y está desactualizada; y por otro lado, el contexto que puede recordar de una conversación está limitado a las 3000 últimas palabras aproximadamente. Aumentar el tamaño de este contexto con el que ChatGPT responde, no se resuelve simplemente con más computación como podríamos pensar. Es un reto científico que se podría abordar con técnicas que permitan memorizar resúmenes de toda la conversación previa. Al fin y al cabo, nosotros tampoco necesitamos memorizar todas las palabras de una conversación para no perder el hilo.
Sin embargo, la falta de veracidad en las respuestas sí que es un factor limitante en el tipo de aplicaciones que podemos construir sobre ChatGPT, que se reducen a dos grandes grupos. El primer grupo consta de aplicaciones que no requieran exactitud en los resultados, por ejemplo, escribir poesía, inspirar relatos de ficción, caracterizar personajes de una historia o sugerir los diálogos de una comedia. Y el segundo grupo lo componen aplicaciones donde podamos comprobar fácilmente la veracidad de los resultados, y en las que aprovechamos las excelentes capacidades de escritura de ChatGPT para asistirnos en tareas rutinarias, aumentando nuestra productividad.
La pregunta es, ¿podemos hacer un ChatGPT que siempre sea veraz en sus respuestas?
Existen dos aproximaciones para tratar de resolver el problema de veracidad. La primera, consiste en especializar ChatGPT al dominio en el que se vaya a usar. Del mismo modo que con las técnicas de InstructGPT OpenAI ha logrado transformar GPT-3 en ChatGPT, para que este se especialice en diálogos y evite generar contenido tóxico, también podemos hacer que aprenda toda la información existente de un área de conocimiento concreta. Esto permitiría disminuir la probabilidad de fallo por debajo del error humano. Un ejemplo de esta aproximación lo tenemos en Med-PaLM, que es un modelo creado a partir de PaLM, un LLM de Google, para que responda a preguntas del ámbito de la medicina. Los resultados son muy prometedores en cuanto al grado de conocimiento almacenado en el modelo conforme aumenta su tamaño, siendo capaz de superar exámenes de medicina. Otro ejemplo de LLM especializado lo encontramos en DoNotPay, una empresa que ha adaptado GPT-3 para gestionar de manera autónoma y en nombre de los usuarios los contratos con grandes corporaciones: darse de baja de un servicio, solicitar la devolución de comisiones o incluso tramitar una demanda.

La segunda aproximación consiste en permitir que ChatGPT consulte fuentes de información externas confiables. De este modo, cuando detecte que tiene que dar una respuesta factual, puede extraer los datos que le faltan de manera autónoma y generar una respuesta más precisa. La ventaja de este método es que podemos actualizar las fuentes de información de manera independiente, para que las respuestas de ChatGPT estén al día sin requerir ningún tipo de entrenamiento adicional. Un ejemplo de esta aproximación lo podemos encontrar en el artículo que ha escrito Stephen Wolfram, donde une ChatGPT con Wolfram Alpha, un motor de búsqueda computacional que proporciona respuestas precisas basadas en datos, en lugar de simplemente enlaces a páginas web relevantes.
Mientras algunas personas disfrutan criticando las limitaciones actuales de ChatGPT, otras como Stephen Wolfram están más interesados en tratar de superarlas. En 2023 seguiremos con expectación cómo evolucionan estos sistemas conversacionales integrando todas estas ideas.
Alerta roja en Google
Tras el momento Imagenet en 2012, Google fue una de las primeras empresas en apostar muy fuerte por la Inteligencia Artificial. Por aquel entonces ya tenían un equipo dedicado a la IA llamado Google Brain, fundado por Andrew Ng, que engordaron contratando a los mejores investigadores en el campo del deep learning (incluyendo al grupo de Geoffrey Hinton responsable del momento Imagenet). También compraron en 2014 la empresa Deepmind, que es otro de los grandes focos de investigación puntera en IA aplicada de los últimos años, junto a OpenAI y Meta AI. Hasta el momento, la prolífica actividad investigadora de Google ha tenido poca repercusión en productos comerciales, según ellos por los problemas de seguridad que pueden ocasionar los grandes modelos, como sesgos indeseados y desinformación entre otros. Solo la publicación de ChatGPT y todo el revuelo que ha causado, donde muchos lo ven como el sustituto natural de las búsquedas en Internet, ha sido capaz de remover a una empresa como Google y provocar un cambio de perspectiva.

Sundar Pichai, CEO de Google, ha anunciado que pondrá disponible sus grandes modelos a través de una API de pago por uso, unos días después de que Microsoft anunciara lo mismo a través de su acuerdo con OpenAI. Además, Google también ha anunciado la vuelta de sus fundadores para apoyar en este cambio de rumbo. De esta manera, entramos en una guerra tecnológica por dominar el mercado de los grandes modelos, al igual que con la llegada de Internet se libró otra por convertirse en el navegador principal de los usuarios (véase Browser wars).
La mala noticia para Google es que OpenAI lleva la delantera ha declarado 100 millones de usuarios activos en el mes de enero y va a empezar a cobrar una suscripción de $20 al mes por el uso de ChatGPT, para el que estima unos ingresos de 1.000 millones de dólares en 2024. La buena noticia para Google es que su apuesta histórica por la IA le permite estar en las mejores condiciones posibles para competir de tú a tú con la alianza formada por OpenAI y Microsoft. Y sin lugar a dudas: que haya competencia es la mejor noticia para los usuarios, porque va a propiciar que estos modelos fundacionales sean cada vez mejores, y sobre estos se puedan crear modelos de negocio todavía por descubrir.
¡Música maestro!
El deep learning es una tecnología que se ha aplicado con éxito en una amplia variedad de campos, incluyendo la música. En este ámbito, se utiliza para tareas como la generación de música, la identificación de estilos y géneros, y la separación de audio. Sin embargo, el avance en la generación de música es aún lento con respecto a la generación de imágenes o de texto debido a varios desafíos que presenta la música. El primero es el guiado de la generación musical mediante texto. Así como una imagen tiene una descripción más o menos fija, una obra musical se puede describir de muchas maneras. Además, la música está compuesta por patrones que se repiten en el tiempo, y estos modelos generativos tienen un alcance corto en la cantidad de datos previamente generados que pueden recordar para generar los siguientes. Y por último, no existen conjuntos de datos de calidad que permitan entrenar estos modelos con pares de texto y música asociada. Es importante destacar que la mayoría de la música está protegida por derechos de autor, lo que también dificulta su disponibilidad para la comunidad investigadora.

Google ha sido capaz de vencer todos estos desafíos y presenta su modelo de lenguaje musical llamado MusicLM, que es capaz de generar música a partir de una descripción. Es una arquitectura basada en 3 redes neuronales que se entrenan de forma independiente y se especializan en distintas partes de la generación: calidad del audio, estructura global de la pieza musical, y cercanía con el texto descriptivo. Junto con el artículo científico, Google publica un conjunto de datos llamado MusicCaps que contiene 5500 pares de música y texto. Dada la variedad de estilos musicales que existen, este conjunto de datos es insuficiente para entrenar este tipo de redes neuronales. Así que la misión de MusicCaps es la de poder evaluar resultados y comparar modelos entre sí, algo también fundamental para el desarrollo del campo de generación musical.
El salto de calidad en base a los ejemplos que han publicado es sorprendente, sobre todo en relación a la cercanía con el texto descriptivo. Se augura un año de avances importantes en IA aplicada a la música.
Este trabajo es una nueva prueba de fuerza por parte de Google, que confirma que tecnológicamente está por delante de otras iniciativas, como OpenAI o Stability AI. Es solo cuestión de tiempo que Google cambie su estrategia y decida entrar en este modelo de negocio que empieza a ser muy lucrativo.
Más info: https://google-research.github.io/seanet/musiclm/examples/
Gracias por leer Explicable. Si te ha gustado esta edición, no te olvides de dar al ♡ y de compartirla por redes sociales o por email con otras personas a las que creas que les pueda gustar.
💥Pero atención…💥
Si no recibieses Explicable directamente en tu correo, revisa bien tu correo no deseado. A veces ocurre que nuestros mensajes se van directamente a ese agujero negro denominado “spam”.
Para evitar que esto ocurra, marca nuestra dirección de correo como “no es spam”.
Si eres usuario de Gmail, revisa también la carpeta de “promociones”, porque puede que también nos hayamos escondido allí y mueve el mensaje al inbox principal. GRACIAS.
I would like to say that this blog really convinced me to do it! Thanks, very good post. https://mcdvoice.boats/